写此此篇文章,以做备忘。
As a note for thoughts of researching Node.js multi-threading solutions.
根据 这里,结合 cluster 和 child_process ,得有此文。
The post is with reference here,and cluster and child_process.
Node.js 与 浏览器的 Javascript 解析器都有同样的问题,就是当遇到高密集度运算时,会出现 UI/进程 阻塞的情况——这里不用论述 Node.js 的架构,一言以敝之,Node.js 根据时势,主动选择了基于单线程的 Event-based 架构。
If you have front-end development background, it should be not hard to understand Javascript process blocking issue as the single-threaded nature of the language in browser. And this happens to Node.js too. It’s going to be a nightmare if you are building a high profile server — surely event-based architecture will not save you.
所以解决方案也是同样的道理,就是要么使用 setTimeout 让 CPU 单线程定时喘口气,或者 *节制地* 的使用多线程并发计算,或者分发到其他 Node.js 节点进行计算。当然,我们更进一步,就是引入“服务分级”。
So, as experience we got from front-end JS and other load balancing solutions, we solve it via setTimeout and/or multi-threading and/or cluster distributing.
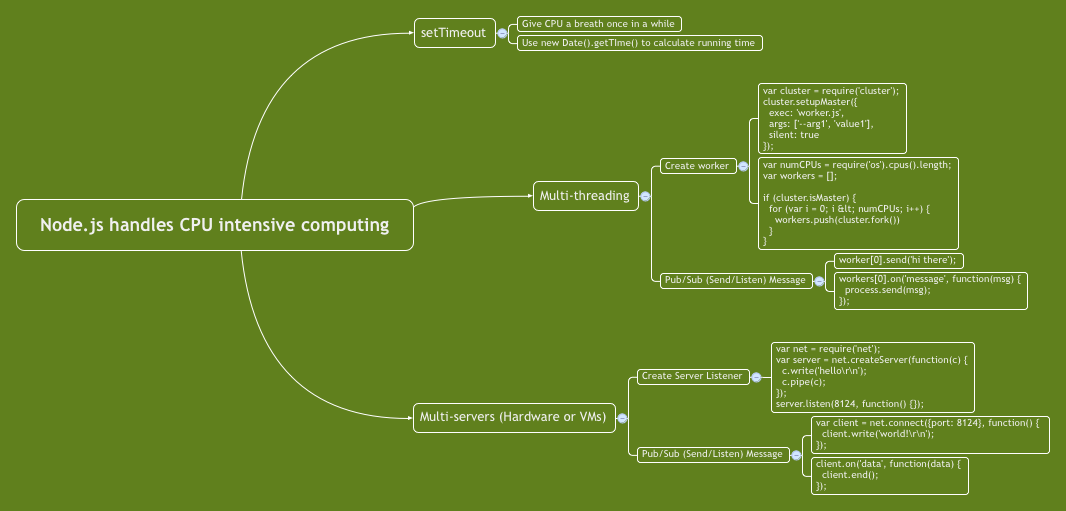
基本思维导图 from Paul
Mindmap from Paul

下面是文字版
Here are exacted texts.
- Node.js handles CPU intensive computing
- setTimeout
- Give CPU a breath once in a while
- Use new Date().getTIme() to calculate running time
- Multi-threading
- Create worker
var cluster = require('cluster'); cluster.setupMaster({ exec: 'worker.js', args: ['--use', 'https'], silent: true });var numCPUs = require('os').cpus().length; var workers = []; if (cluster.isMaster) { for (var i = 0; i < numCPUs; i++) { workers.push(cluster.fork()) } } - Pub/Sub (Send/Listen) Message
worker[0].send('hi there');workers[0].on('message', function(msg) { process.send(msg); });
- Create worker
- Multi-servers (Hardware or VMs)
- Create Server Listener
var net = require('net'); var server = net.createServer(function(c) { c.write('hello\r\n'); c.pipe(c); }); server.listen(8124, function() {}); - Pub/Sub (Send/Listen) Message
var client = net.connect({port: 8124}, function() { client.write('world!\r\n'); });client.on('data', function(data) { client.end(); });
- Create Server Listener
- setTimeout
更多关于“服务等级”
About “Service Grade”
“服务等级”是借用 Grade of service/QoS 的概念。
Yes, it comes from Grade of Service and QoS.
基本观点
Basic ideas
再好的服务器资源划分,也不可能完美的解决所有的请求。所以我们可能要给已经创建的集群服务节点进一步分类出子集群,不同的子集群处理不同优先级的任务。同时,我们给Master节点添加任务 dispatching 层。在这个层里,我们给每个任务按照优先级进行归类,以分发到不同的子集群进行处理。
There is almost no server solution for handing all requests perfectly. So we may need to categorize our cluster nodes into sub-clusters, to enable them to handle tasks according to their priorities. At the meantime, we also need to add a task dispatcher to the master/controller node to group and distribute the tasks of task list as well.
任务分类标准
Categorizing standard
为了简化任务分类,我们借助时间管理的概念,给计算任务分成重要与紧急双维度,所以第一优先级是重要并且紧急的,第二是重要不紧急的,第三是紧急不重要的,第四是不紧急不重要的。我们无条件地给任务队列进行排序,确保高优先级的任务可以随时被处理;而低优先级的任务可以随时挂起,以允许插队。
To make things simple, we borrow ideas of time management to group our computing tasks into 4 kinds according to their Importance and Urgence. Thus, the top priority is Important & Urgent task, second is Important & No-urgent, Urgent & No-important goes to the third, and No-urgent & No-important is the last. We need to make sure the high priority tasks are always proceeded first. The policy applying to that is all low priority tasks should be suspendible once any new higher priority tasks coming in with unconditional task prioritizing principle.
更多
More
更多集群协助、失败处理等,这里就不多说了。
Don’t want to research more with cluster failure/collaborations here.
